I processed 1458 models in this spreadsheet (see models tab). As mentioned in my previous post, these are the parameters:
- model_number – the identification number
- batch_size – the size of the batch. 8 or 16
- filters1 – the number of filters for layer 1. (possible values 32,64 or 128)
model.add(Conv2D(filters=filters1, - dropout1 – Dropout (if greater than 0) (possible values 0,0.25,0.5)
if(dropout1>0):
model.add(Dropout(dropout1))
- filters2 – the number of filters for layer 2. (32,64 or 128)
- dropout2 – dropout for layer 2. (0,0.25,0.5)
- filters3 – the number of filters for layer 3. (32,64 or 128)
- dropout3 – dropout for layer 3. (0,0.25,0.5)
- loss – the result of running the model.
- accuracy – (as above.)
A review of the spreadsheet shows that many of the models I ran have poor accuracy, even as low as 1:3 (0.333333333333333) to predict a match between three coin obverse portraits (Elizabeth II, George VI and Abraham Lincoln). I did find some models with an accuracy above 80% yet I wanted to see if there were patterns I could use to improve my set of models. So I used a Seaborn heatmap of the models (below) for batch sizes of 8,16 and both together.
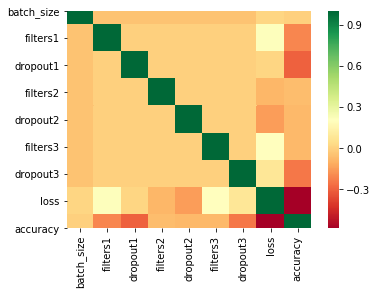
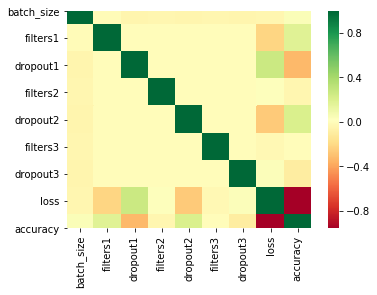
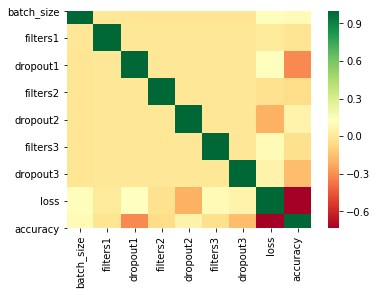
The heatmap for loss and accuracy to the model parameters in the last two rows shows there is a slightly negative relationship between accuracy and dropout1. It is possible it would be more efficient to use dropout values of 0 or 0.25 and not 0.5 when running these models again. It also seems like there is a slightly positive relationship between batch size and accuracy possibly indicating that larger batch sizes may lead to more accurate models. I have been running a set of models with a batch size of 32 to see if this pattern becomes stronger. (same spreadsheet, models tab.) I am also going to validate my approach through additional personal (not machine) learning.