This week’s progress is represented by the simple list below that shows which issues of the Equity contain information about Alonzo Wright.
Alonzo Wright
83471_1883-10-25
83471_1884-11-27
83471_1885-01-22
83471_1885-07-16
83471_1886-03-18
83471_1894-01-11
83471_1898-09-01
83471_1900-03-29
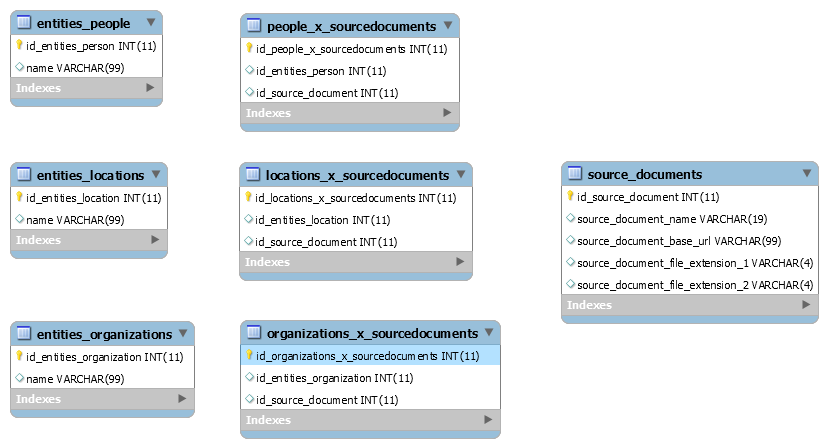
The list is generated from a database containing all of the entities found in the Equity that I have processed so far. Here is the select statement:
Select entities_people.name, source_documents.source_document_name, source_documents.source_document_base_url, source_documents.source_document_file_extension_1 from entities_people left join people_x_sourcedocuments on entities_people.id_entities_person = people_x_sourcedocuments.id_entities_person left join source_documents on people_x_sourcedocuments.id_source_document = source_documents.id_source_document where entities_people.name = "Alonzo Wright" group by source_documents.source_document_name order by entities_people.name
Currently I am processing issue 981 of the Equity published on 21 March, 1901 and each issue takes several minutes of processing time. Although I have more than 5000 more issues to go before I meet my processing goal this is solid progress compared to earlier this week.
Overcoming memory issues.
I had a sticky problem where my R Equity processing program would stop due to memory errors after processing only a few editions. Given I want to process about 6000 editions, it would be beyond tedious to restart the program after each error.
I modified the database and program to store a processing status so that the program could pick up after the last edition it finished rather than starting at the first edition each time and this was successful, but it wasn’t a fix.
Since I was dealing with this error:
Error in .jnew("opennlp.tools.namefind.TokenNameFinderModel", .jcast(.jnew("java.io.FileInputStream", :java.lang.OutOfMemoryError: GC overhead limit exceeded
I tried to reduce the amount of garbage collection/GC that Java was doing. I removed some of the dbClearResult(rs) statements with the theory that this was causing the underlying Java to do garbage collection and this seemed to to work better.
Later I got another error message:
java.lang.OutOfMemoryError: Java heap space
So I upped my memory usage here:
options(java.parameters = "-Xmx4096m")
Per this article: I tried this:
options(java.parameters = "-Xms4096m -Xmx4096m")
I still got “java.lang.OutOfMemoryError: GC overhead limit exceeded”.
I commented out all of the output to html files which was part of the original program. This seemed to improved processing.
#outputFilePeopleHtml <- "equityeditions_people.html" #outputFilePeopleHtmlCon<-file(outputFilePeopleHtml, open = "w")
These files were large, maybe too large. Also, with the re-starting of the program, they were incomplete because they only had results from the most recent run of the program. To generate output files, I’ll write a new program to extract the data from the database after all the editions are processed.
After all that though, I still had memory errors and my trial and error fixes were providing only marginal improvement if any real improvement at all.
Forcing garbage collection
Per this article, I added this command to force garbage collection in java and free up memory.
gc()
But I still got out of memory errors. I then changed the program to remove all but essential objects from memory and force garbage collection after each edition is processed:
objectsToKeep<-c("localuserpassword","inputCon", "mydb", "urlLine", "entities", "printAndStoreEntities" )
rm(list=setdiff(ls(),objectsToKeep ))
gc()
After doing this the processing program has been running for several hours now and has not stopped. So far, this has been the best improvement. The processing program has just passed March 1902 and it has stored its 61,906th person entity into the database.