I have been reviewing the list of entities extracted from the editions of The Equity and have seen errors I could have corrected in the finding aid. One of them is that some entities appear in the same list twice. An example comes from this page listing locations below.
Fort Coulongc
Fort Coulonge Williams
Fort Coulonge
Fort CoulongeSt. John’s
Fort Coulongo
<–snip–>
Fort Coulonge St.
Fort Coulonge Tel.
Fort Coulonge
Fort Coulonge – River
Fort Coulonge – St. Andrew
Why is this? The first entity for Fort Coulonge has a tab character (ASCII code 9) separating the two words while the second one listed has a space (code 32), as expected. In this finding aid, each entity is meant to be unique to make it easier to reference and so this is a problem. I could correct this in the database with SQL UPDATE statements to merge the information for entities containing tab characters with the entity containing spaces, but it’s also an opportunity to reprocess the data from scratch and make some more corrections.
The last time I processed The Equity for entities it took about 2 weeks of around the clock processing, counting time when the program repeatedly stopped due to out of memory errors. However, with performance improvements, I expect reprocessing will be faster.
I would also like to add some spelling correction for OCR errors. The first spelling correction I tried was the method that comes from Rasmus Bååth’s Research Blog and Peter Norvig’s technique. A large corpus of words from English texts is used as the basis for correcting the spelling of a word. The word to be checked is compared to the words in the corpus and a match based on probability is proposed. My results from this technique did not offer much correction and in fact produced some erroneous corrections. I think this is because my person, location and organization entities often contain names.
I tried the R function which_misspelled() which did not produce an improvement in spelling correction either. I’ve spent a fair amount of time on this, is this a failure?
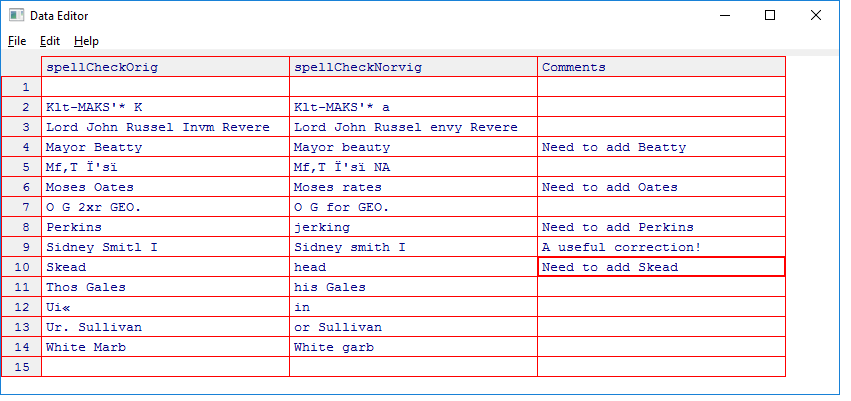
Peter Norvig’s technique is trainable. Adding additional words to Norvig’s corpus used for spell checking seems to give better results. I even got a few useful corrections such as changing Khawville to shawville. To start to train the Norvig spell checker I entered all of the communities in Quebec listed on this Wikipedia category. Then I viewed the output as each term was checked so see if the Norvig spell checker was failing to recognize a correctly spelled word. An example of this is when the name Beatty gets corrected to beauty. I added the correctly spelled names that Norvig’s method was not picking up to his corpus.
Below is a sample of terms I have added to Norvig’s corpus to improve the spell check results for entities found in The Equity.
Ottawa, Porteous, Hiver, Du, Lafleur, Varian, Ont, Mercier, Duvane, Hanlan, Farrell, Robertson, Toronto, Jones, Alexandria, Chicago, England, London, Manchester, Renfrew, Pontiac, Campbell, Forresters Falls, UK, Cuthbertson, Steele, Gagnon, Fort Coulonge, Beresford, Carswell, Doran, Dodd, Allumette, Nepean, Rochester, Latour, Lacrosse, Mousseau, Tupper, Devine, Carleton, Laval, McGill, Coyne, Hodgins, Purcival, Brockville, Eganville, Rideau, McLean, Hector, Langevin, Cowan, Tilley, Jones, Leduc, McGuire
Below is an example of the output from the spelling correction using Norvig’s method. As you can see, I need to add terms from lines 4,6,8 and 10 because the Norvig method is returning an incorrect result. Even then, this method may still return an error for a correctly spelled name. Despite adding “McLean” to the corpus, this method still corrects “McLean” as “clean”.
The full R program is here. Below is the detail of the portion of the function used for spelling correction
# Read in big.txt, a 6.5 mb collection of different English texts.
raw_text <- paste(readLines("C:/a_orgs/carleton/hist3814/R/graham_fellowship/norvigs-big-plus-placesx2.txt"), collapse = " ")
# Make the text lowercase and split it up creating a huge vector of word tokens.
split_text <- strsplit(tolower(raw_text), "[^a-z]+")
# Count the number of different type of words.
word_count <- table(split_text)
# Sort the words and create an ordered vector with the most common type of words first.
sorted_words <- names(sort(word_count, decreasing = TRUE))
setwd("C:/a_orgs/carleton/hist3814/R/graham_fellowship")
#Rasmus Bååth's Research Blog
#http://www.sumsar.net/blog/2014/12/peter-norvigs-spell-checker-in-two-lines-of-r/
correctNorvig <- function(word) {
# Calculate the edit distance between the word and all other words in sorted_words.
edit_dist <- adist(word, sorted_words)
# Calculate the minimum edit distance to find a word that exists in big.txt
# with a limit of two edits.
min_edit_dist <- min(edit_dist, 2)
# Generate a vector with all words with this minimum edit distance.
# Since sorted_words is ordered from most common to least common, the resulting
# vector will have the most common / probable match first.
proposals_by_prob <- c(sorted_words[ edit_dist <= min(edit_dist, 2)])
# In case proposals_by_prob would be empty we append the word to be corrected...
proposals_by_prob <- c(proposals_by_prob, word)
# ... and return the first / most probable word in the vector.
proposals_by_prob[1]
}
<!--- snip ---- much of the program is removed --->
# correctedEntity is what will be checked for spelling
# nameSpellChecked is the resulting value of the spelling correction, if a correction is found.
nameSpellChecked=""
correctedEntityWords = strsplit(correctedEntity, " ")
correctedEntityWordsNorvig = strsplit(correctedEntity, " ")
#sometimes which_misspelled() fails and so it is in a tryCatch()
misSpelledWords <-tryCatch(
{
which_misspelled(correctedEntity, suggest=TRUE)
},
error=function(cond) {
NULL
},
warning=function(cond) {
NULL
},
finally={
NULL
})
if(is.null(misSpelledWords)){
#The R spell checker has not picked up a problem, so no need to do further checking.
misSpelled=FALSE
} else {
for(counter in 1:length(misSpelledWords[[1]])){
misSpelled=TRUE
wordNum = as.integer(misSpelledWords[[1]][counter])
correctedEntityWords[[1]][wordNum] = misSpelledWords[counter,3]
correctedEntityWordsNorvig[[1]][wordNum] = correctNorvig(correctedEntityWordsNorvig[[1]][wordNum])
}
correctedEntitySpellChecked = paste(correctedEntityWords[[1]],collapse=" ")
correctedEntityNorvig = paste(correctedEntityWordsNorvig[[1]],collapse=" ")
nameSpellChecked=""
if(!str_to_upper(correctedEntity)==str_to_upper(correctedEntityNorvig)){
#We have found a suggested correction
nameSpellChecked=correctedEntityNorvig
print(paste(correctedEntity,misSpelled,correctedEntitySpellChecked,correctedEntityNorvig,sep=" --- "))
#keep a vector of the words to make into a dataframe so that we can check the results of the spell check. Remove this after training of the spell checker is done.
spellCheckOrig<-c(spellCheckOrig,correctedEntity)
spellCheckMisSpelled<-c(spellCheckMisSpelled,misSpelled)
spellCheckCorrect<-c(spellCheckCorrect,correctedEntitySpellChecked)
spellCheckNorvig<-c(spellCheckNorvig,correctedEntityNorvig)
}
}
#Clean up any symbols that will cause an SQL error when inserted into the database
nameSpellCheckedSql = gsub("'", "''", nameSpellChecked)
nameSpellCheckedSql = gsub("’", "''", nameSpellCheckedSql)
nameSpellCheckedSql = gsub("\'", "''", nameSpellCheckedSql)
nameSpellCheckedSql = gsub("\\", "", nameSpellCheckedSql, fixed=TRUE)
The next step is to finish reprocessing the Equity editions and use the corrected spelling field to improve the results in the “possible related entities” section of each entity listed on the web site for the finding aid.
I’m glad you understand all this and can make all the magic happen! 🙂 Thank you so very much!