Since the start of September I have been working to improve my image classification model. The positive result is that I have a model that is capable of categorizing 3 different types of coins, however the model is not yet as accurate as it needs to be. For reference here is my working code
Categorizing three different types of coin images.
I have added photos of Abraham Lincoln to the collection of coin photos I am using for training. Each class of photo is “one hot label” encoded to give it an identifier that can be used in the model: 1,0,0 = Elizabeth; 0,1,0 = George VI and 0,0,1 = Abraham Lincoln. (Continuing this pattern, additional classes of coins can be added for training.) Below is the code that does this based on the first three characters of the photo’s file name.
def one_hot_label(img):
label = img.split('.')[0]
label = label[:3]
if label == 'eII':
ohl = np.array([1,0,0])
elif label == 'gvi':
ohl = np.array([0,1,0])
elif label == 'lin':
ohl = np.array([0,0,1])
return ohl

The model I have trained can recognize Abraham Lincoln more times that it does not.

predict_for('/content/drive/My Drive/coin-image-processor/portraits/test/all/linc4351.png') produced a result of [0. 0. 1.], which is correct. The model fails to accurately predict some of the other images of Lincoln.
Model Accuracy
When training the model I monitor the loss and accuracy for both training and validation. Validation accuracy is where the model checks its effectiveness against a set of validation images. Training accuracy is a measure of how well the model is performing using its training data. A model is functioning well if its training accuracy and validation accuracy are both high .
Epoch 16/150 13/13 [==============================] - 0s 23ms/step - loss: 0.8050 - acc: 0.5769 - val_loss: 10.7454 - val_acc: 0.3333
As shown above, at this point in the training of this model, the training accuracy (acc:) is low (57.6%) and the validation accuracy (val_acc:) is even lower (33%). For an image prediction between 3 different types of coins, this model is validated to be as accurate as rolling a die.
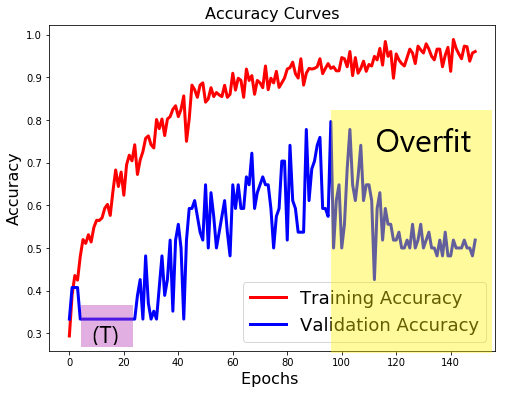
The red line of the training accuracy in the graph above shows a model that becomes more accurate over time. The accuracy of the model is very low initially, but it does climb almost continuously.
The validation accuracy of the model also begins quite low. Consider the area of the graph inside the magenta box denoted by (T). During this training, val_acc stalls at 33% between epochs 5 and 25. During my experiments with different model configurations, if I saw this stall happen I would terminate the training to save time. Considering what happened here, I should let the models run longer. This model eventually achieved a validation accuracy of 78%, the best result I had in the past couple of days.
Overfitting
The validation accuracy of this model peaks at epoch 88. As it declines, the training accuracy of the model continues a trend to higher accuracy. This is a sign that the model is overfitting and training for features that are present in the training data but won’t be generally present for other images. An overfit model is not useful for recognizing images from outside of its training set. This information is useful since it signifies that this model should be trained for approximately 88 epochs and not 150. At the same time, this particular model still needs work. Even with a validation accuracy of 77%, the model is still likely overfit given it has a training accuracy of 90%. So it is likely that this model will make errors of prediction when used with new images of our coin subjects.