Last week’s research focused on getting notices from the British Gazette via their API. The notices are searchable and returned as XML which could be handled easily as a dataFrame in R.
This week’s focus is a web site that I can’t find an API for, the National Library of Wales’ Welsh Newspapers Online. This site is a tremendous source of news stories and it easy for a person to search and browse. I have asked the Welsh Library if the web site has an API. In the meantime, this week’s program uses search result webpages to get data. It’s a much uglier and error prone process to reliable get data out of a web page, but I expect the benefits of doing that will save me some time in pulling together newspaper articles for research so that I can focus on reading them rather than downloading them. I hope this approach is useful for others. Here is the program.
To search Welsh Newspapers Online using R, a URL can be composed with these statements:
searchDateRangeMin = "1914-08-03"
searchDateRangeMax = "1918-11-20"
searchDateRange = paste("&range%5Bmin%5D=",searchDateRangeMin,"T00%3A00%3A00Z&range%5Bmax%5D=",searchDateRangeMax,"T00%3A00%3A00Z",sep="")
searchBaseURL = "http://newspapers.library.wales/"
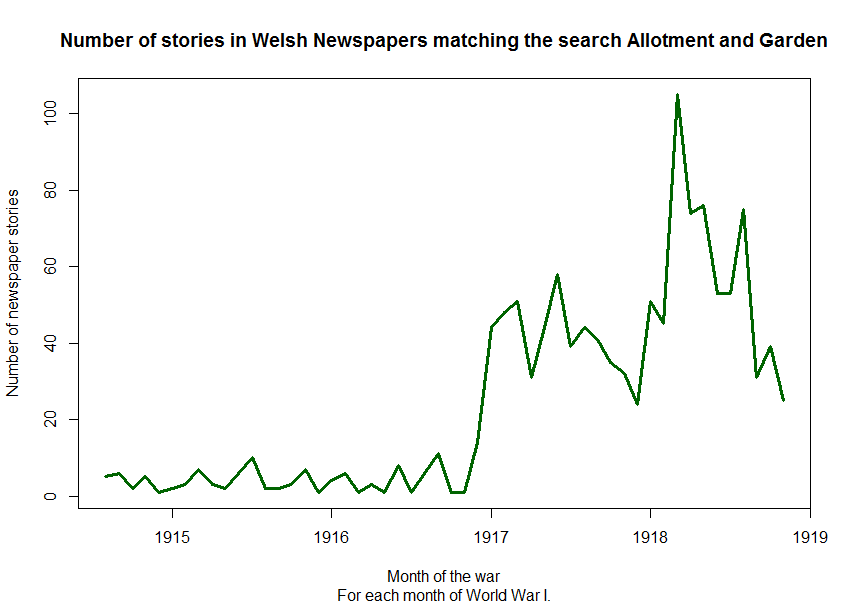
searchTerms = paste("search?alt=full_text%3A%22","allotment","%22+","AND","+full_text%3A%22","society","%22+","OR","+full_text%3A%22","societies","%22",sep="")
searchURL = paste(searchBaseURL,searchTerms,searchDateRange,sep="")
These assemble the Search URL:
http://newspapers.library.wales/search?alt=full_text%3A%22allotment%22+AND+full_text%3A%22society%22+OR+full_text%3A%22societies%22&range%5Bmin%5D=1914-08-03T00%3A00%3A00Z&range%5Bmax%5D=1918-11-20T00%3A00%3A00Z
This search generates 1,009 results. To loop through them in pages of 12 results at a time this loop is used:
for(gatherPagesCounter in 84:(floor(numberResults/12)+1)){
How does the program know the number of results returned by the search? It looks through the search results page line by line until it finds a line like:
<input id="fl-decade-0" type="checkbox" class="facet-checkbox" name="decade[]" value="1910" facet />
If you like, take a look at the source of this page and find the line above by searching for 1910.
The line above is unique on the page and does not change regardless of how many search results. Following that line we have the one below containing the number of results:
<label for="fl-decade-0"> 1910 - 1919 <span class="facet-count" data-facet="1910">(1,009)</span></label>
Here is the part of the program that searches for the line above and parses the second line to get the numeric value of 1009 we want:
# find number of results
for (entriesCounter in 1:550){
if(thepage[entriesCounter] == '<input id=\"fl-decade-0\" type=\"checkbox\" class=\"facet-checkbox\" name=\"decade[]\" value=\"1910\" facet />') {
print(thepage[entriesCounter+1])
tmpline = thepage[entriesCounter+1]
tmpleft = gregexpr(pattern ='"1910',tmpline)
tmpright = gregexpr(pattern ='</span>',tmpline)
numberResults = substr(tmpline, tmpleft[[1]]+8, tmpright[[1]]-2)
numberResults = trimws(gsub(",","",numberResults))
numberResults = as.numeric(numberResults)
}
}
Getting this information returned from an API would be easier to work with, but we can handle this.
For testing purposes, I’m using 3 pages of search results for now. Here is a sample of the logic used in most of the program:
for(gatherPagesCounter in 1:3){
thepage = readLines(paste (searchURL,"&page=",gatherPagesCounter,sep=""))
# get rid of the tabs
thepage = trimws(gsub("\t"," ",thepage))
for (entriesCounter in 900:length(thepage)){
if(thepage[entriesCounter] == '<h2 class=\"result-title\">'){
<...snip...>
entryTitle = trimws(gsub("</a>","",thepage[entriesCounter+2]))
A page number is appended to the search URL noted above…
thepage = readLines(paste(searchURL,"&page=",gatherPagesCounter,sep=""))
…so that we have a URL like below and the program can step through pages 1,2,3…85:
http://newspapers.library.wales/search?alt=full_text%3A%22allotment%22+AND+full_text%3A%22society%22+OR+full_text%3A%22societies%22&range%5Bmin%5D=1914-08-03T00%3A00%3A00Z&range%5Bmax%5D=1918-11-20T00%3A00%3A00Z&page=2
This statement removes tab characters to make each line cleaner for the purposes of looking for the lines we want:
thepage = trimws(gsub("\t"," ",thepage))
The program loops through the lines on the page looking for each line that signifies the start of an article returned from the search: <h2 class=”result-title”>
for (entriesCounter in 900:length(thepage)){
if(thepage[entriesCounter] == '<h2 class=\"result-title\">'){
Once we know which line number <h2 class=”result-title”> is on, we can get items like the article title that happen to be 2 lines below the line we found:
entryTitle = trimws(gsub("</a>","",thepage[entriesCounter+2]))
This all breaks to smithereens if the web site is redesigned, however it’s working ok for my purposes here which are temporary. I hope it works for you. This technique can be adapted to other similar web sites.
Download each article:
For each search result returned the program also downloads the text of the linked article. As it does that, the program takes a pause for 5 seconds so as not to put a strain on the web servers at the other end of this.
# wait 5 seconds - don't stress the server
p1 <- proc.time()
Sys.sleep(5)
proc.time() - p1
Results of the program:
- A comma separated value (.csv) file of each article with the newspaper name, article title, date published, URL and a rough citation.
- A separate html file with the title and text of each article so that I can read it off-line.
- An html index to these files for easy reference.
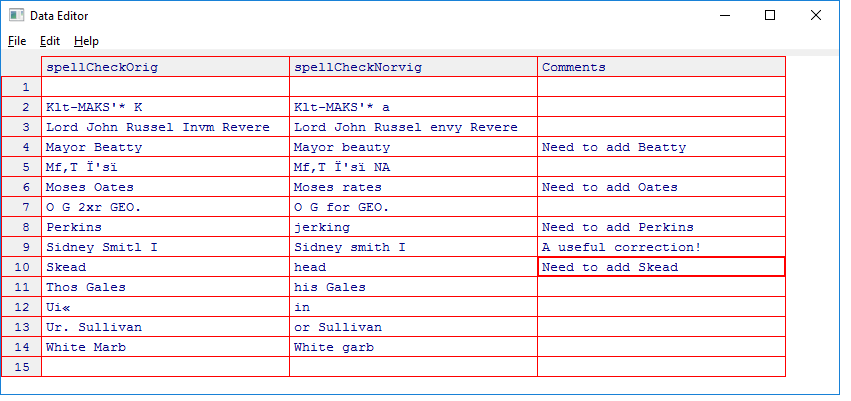
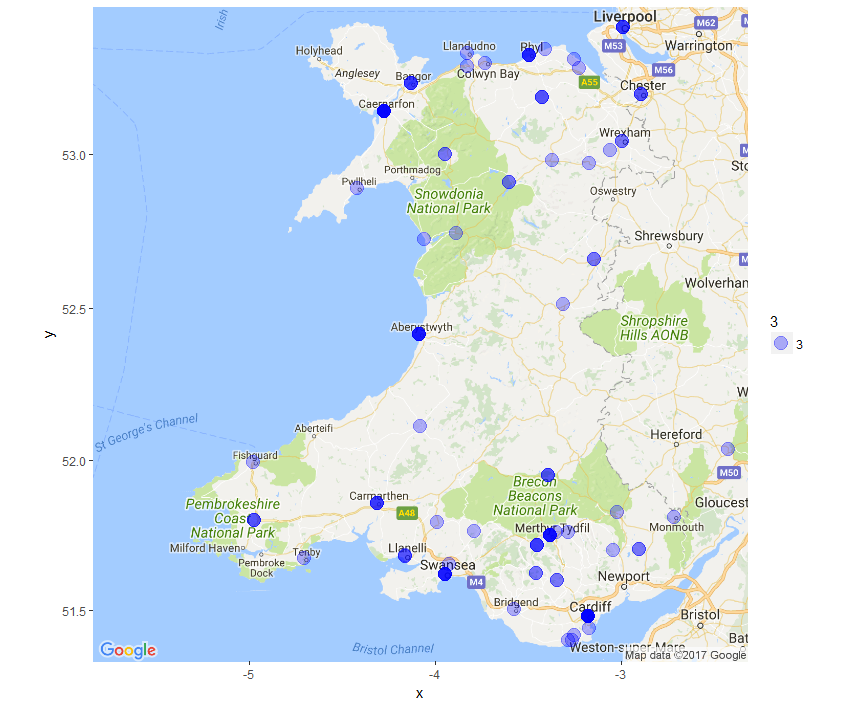
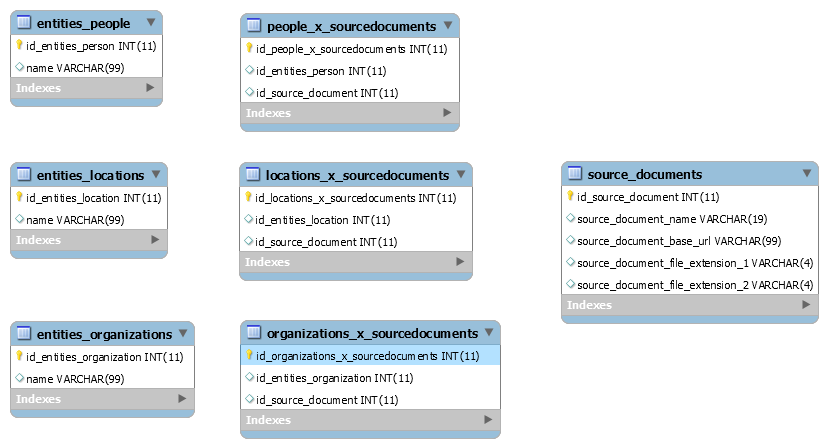
Reading through the articles I can make notes in a spreadsheet listing all of the articles, removing the non-relevant ones and classifying the others. I have applied natural language processing to extract people, location and organization entities from the articles, but I am still evaluating if that provides useful data due to the frequency of errors I’m seeing.
It’s time to let this loose!