This is a note about how I connected to box.com using its API so that a python program could download images and meta data.
Details of the API are here https://developer.box.com/en/guides/authentication/oauth2/with-sdk/
To connect to Box, I needed to make an app. See the link “My Apps” in the SDK link above.
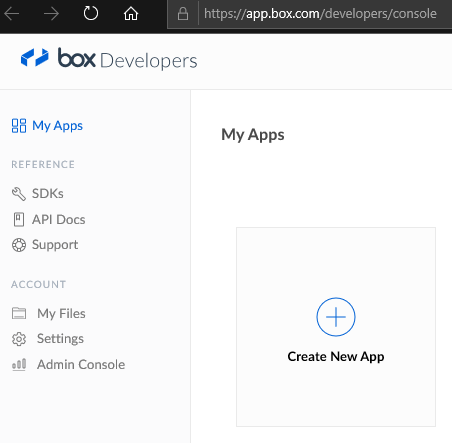
Create a new app.
Give your app a name.
I used OAuth 2.0 Authentication
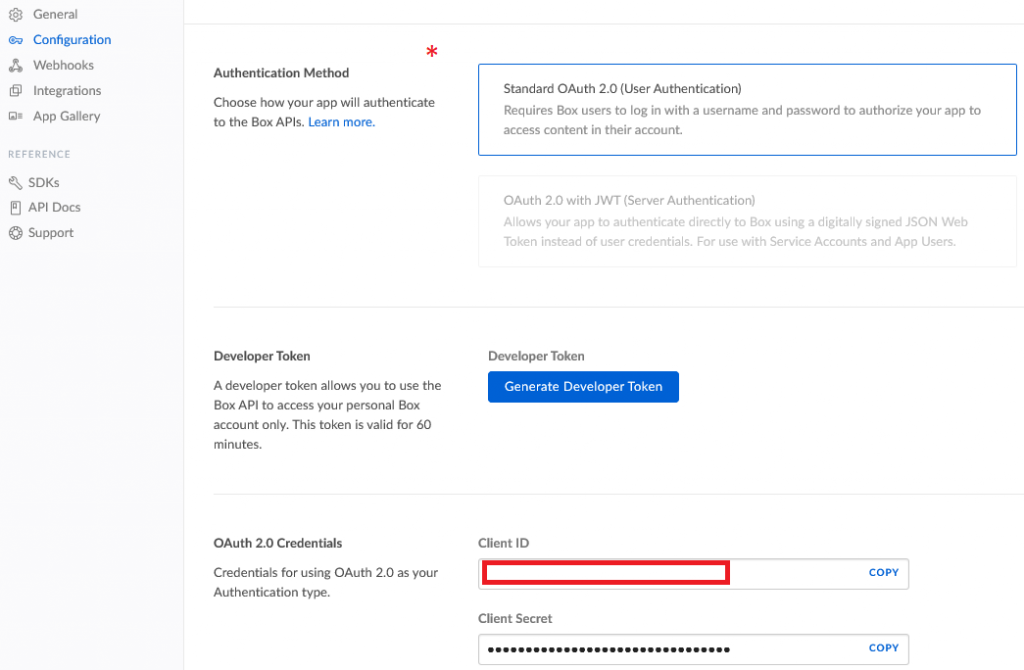
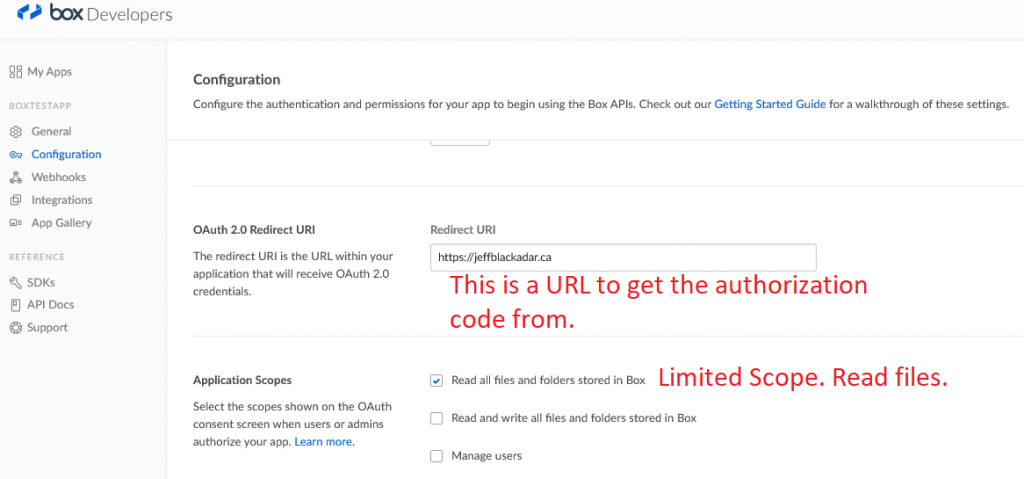
I put the client_id and client_secret values into a json file that looks like this:
{
"client_id":"ryyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy",
"client_secret":"Vzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz"
}Here is the code to connect:
!pip install boxsdk
!pip install auth
!pip install redis
!pip install mysql.connector
!pip install requests
from boxsdk import OAuth2
import json
#Set the file we want to use for authenticating a Box app
#The json file stores the client_id and client_secret so we don't have it in the code.
# The json file looks like this:
#{
#"client_id":"___the_codes_for_client_id___",
#"client_secret":"___the_codes_for_client_secret___"
#}
oauth_settings_file = 'C:\\ProgramData\\box_app_test.json'
with open(oauth_settings_file, "r") as read_file:
oauth_data = json.load(read_file)
print(oauth_data["client_id"])
print(oauth_data["client_secret"])
oauth = OAuth2(
client_id=oauth_data["client_id"],
client_secret=oauth_data["client_secret"]
)
auth_url, csrf_token = oauth.get_authorization_url('https://jeffblackadar.ca')
print("Click on this:")
print(auth_url)
print(csrf_token)
print("Copy the code that follows code= in the URL. Paste it into the oauth.authenticate('___the_code___') below. Be quick, the code lasts only a few seconds.")I ran the code above in a Jupyter notebook. The output is:
ryyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy
Vzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz
Click on this:
https://account.box.com/api/oauth2/authorize?state=box_csrf_token_Qcccccccccccccccccccccc&response_type=code&client_id=ryyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy&redirect_uri=https%3A%2F%2Fjeffblackadar.ca
box_csrf_token_Qcccccccccccccccccccccc
Copy the code that follows code= in the URL. Paste it into the oauth.authenticate('the_code') below. Be quick, the code lasts only a few seconds.You will notice the Redirect URI set above appears when the URL above is clicked. But first you must authenticate with Box.com using your password to make sure only authorized users read your content.
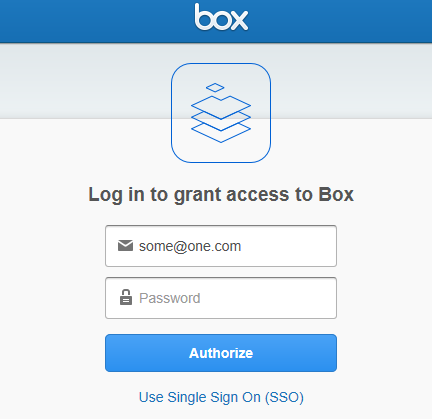
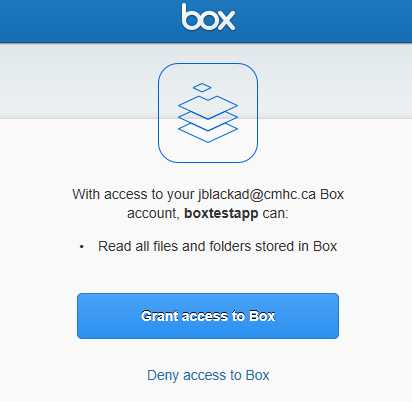

Paste the code above into the statement below. You need to work quickly, the code is valid for a few seconds only. There is a better way to do this, but this is what is working at this time, please let me know of improvements.
from boxsdk import Client
# Make sure that the csrf token you get from the `state` parameter
# in the final redirect URI is the same token you get from the
# get_authorization_url method to protect against CSRF vulnerabilities.
#assert 'THE_CSRF_TOKEN_YOU_GOT' == csrf_token
access_token, refresh_token = oauth.authenticate('qzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz')
client = Client(oauth)Then run this test. It will list all of the files in the folders on box.com.
def process_subfolder_test(client, folder_id, folder_name):
print("this folder: "+folder_name)
items = client.folder(folder_id=folder_id).get_items()
for item in items:
print('{0} {1} is named "{2}"'.format(item.type.capitalize(), item.id, item.name))
if(item.type.capitalize()=="Folder"):
process_subfolder_test(client, item.id,folder_name+"/"+item.name)
if(item.type.capitalize()=="File"):
#print(item)
print('File: {0} is named: "{1}" path: {2} '.format(item.id, item.name, folder_name+"/"+item.name))
return
process_subfolder_test(client, '0',"")
Here is the test output:
this folder:
Folder 98208868103 is named "lop"
this folder: /lop
Folder 98436941432 is named "1963"
this folder: /lop/1963
File 588118649408 is named "Elizabeth II young 2019-08-10 15_41_20.591925.jpg"
File: 588118649408 is named: "Elizabeth II young 2019-08-10 15_41_20.591925.jpg" path: /lop/1963/Elizabeth II young 2019-08-10 15_41_20.591925.jpg
File 588114839194 is named "Elizabeth II young 2019-08-10 15_41_52.188758.jpg"
File: 588114839194 is named: "Elizabeth II young 2019-08-10 15_41_52.188758.jpg" path: /lop/1963/Elizabeth II young 2019-08-10 15_41_52.188758.jpg
File 587019307270 is named "eII2900.png"
File: 587019307270 is named: "eII2900.png" path: /lop/eII2900.png
File 587019495720 is named "eII2901.png"
File: 587019495720 is named: "eII2901.png" path: /lop/eII2901.png
File 587019193229 is named "eII2903.png"
File: 587019193229 is named: "eII2903.png" path: /lop/eII2903.png