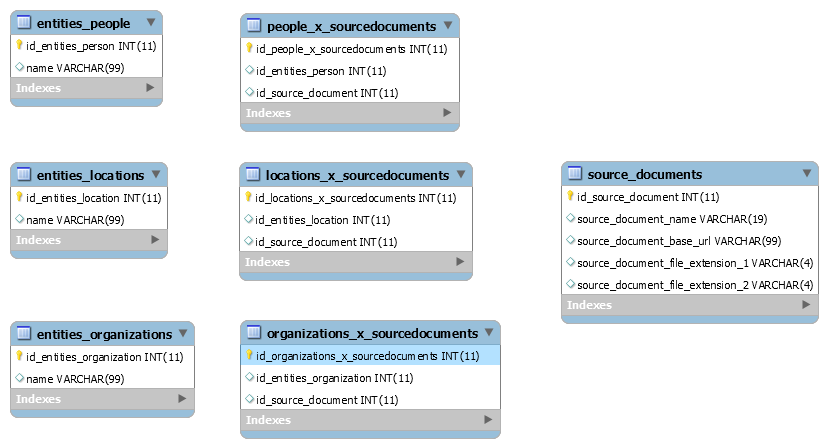
This week I added a small relational database using MySQL to the project and have stored a record for each issue, one for each of the entities found in the issue as well as a cross reference table for each type of entity.
Problems
I have run into memory issues. I am able to process several dozen issues and then get:
Error in .jnew("opennlp.tools.namefind.TokenNameFinderModel", .jcast(.jnew("java.io.FileInputStream", :java.lang.OutOfMemoryError: GC overhead limit exceeded
In my R Program, I have tried this
options(java.parameters = "- Xmx2048m")
However, the memory issue resurfaces on subsequent runs. I probably need to clean up the variables I am using better. I would appreciate a diagnosis of the cause of this if you can help.
I have also had SQL errors when trying to insert some data from the OCR’d text such as apostrophes (‘) and backslashes (\) and so I replace those characters with either an html glyph like ' or empty spaces:
entitySql = gsub("'", "'", entity)
entitySql = gsub("\n", "", entitySql)
entitySql = gsub("\'", "", entitySql)
entitySql = gsub("\\", "", entitySql, fixed=TRUE)
I also need to control for data to ensure not to try to insert an entity I already have in what is supposed to be a list of unique entities to avoid the error I have below:
Error in .local(conn, statement, ...) : could not run statement: Duplicate entry 'Household Department ; Health Department ; Young Folks’ Depart' for key 'name_UNIQUE'
Future plans for this project
This week I plan to continue making adjustments to the program to make it run better and consume less memory. I also want to start generating output from the database so that I can display all of the issues a particular entity (person, location or organization) appears in.
Make the process repeatable
Later, I want to take this program and database and reset it to work on another English language newspaper that has been digitized. I plan to document the set up so that it can be used more easily by other digital historians.
Clean up of text errors from OCR
In the OCR’d text of The Equity there are many misspelled words due to errors from the OCR process. I would like to correct these errors but there are two challenges to making corrections by redoing the OCR. The first challenge is volume, there are over 6000 issues to The Equity to deal with. The second is that I was not able to achieve a better quality OCR result than what is available on the Province of Quebec’s Bibliotheque and Archives web site. In a previous experiment I carefully re-did the OCR of a PDF of an issue of The Equity. While the text of each column was no longer mixed with other columns the quality of the resulting words was no better. The cause of this may be that the resolution of the PDF on the website is not high enough to give a better result and that to truly improve the OCR I would need access to a paper copy to make a higher resolution image of it.
While it seems that improving the quality of the OCR is not practical for me, I would still like to clear up misspellings. One idea is to apply machine learning to see if it is possible to correct the text generated by OCR. The article OCR Error Correction Using Character Correction and Feature-Based Word Classification by Ido Kissos and Nachum Dershowitz looks promising, so I plan to work on this a little later in the project. Perhaps machine learning can pick up the word pattern and correct “Massachusetts Supremo Court” found in the text of one of the issues.