Image hashing is a process to match images through the use of a number that represents a very simplified form of an image, like this one below.
Original image before image hashing. Images courtesy of Pompeii in Pictures.
First, the color of the image is simplified. The image is converted to grayscale. See below:
Image converted to grayscale. Images courtesy of Pompeii in Pictures.
Next, the image is simplified by size. It is resized 9 pixels wide by 8 pixels high.
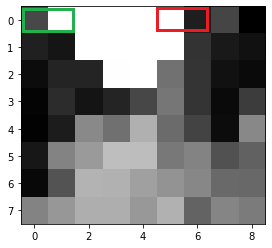
Image resized to 9 pixels wide by 8 pixels high. The green and red rectangles are relevant to describe the next step.
Adrian Rosebrock uses a differential hash based on brightness to create a binary number of 64 bits. Each bit is 1 or 0. Two pixels next to each other horizontally are compared: left and right. If right is brighter, bit = 1. Bit = 0 if left is brighter. See below:
The result of the image hash for the image above. The 1 inside the green square is the result of the comparison between the 2 pixels in the green rectangle in the picture above. The same thing is true for the o inside the red square. Inside the red rectangle two images above, the pixel on the left is brighter, so 0 is the result.
This process produces a 64bit binary number: 0101001100000011101001111000101110011101000011110000001001000011
This converts to decimal 5981808948155449923.
Matches
A match of copies of an image.An interesting match of similar images.
I am building a project to detect wall construction types from images of Pompeii. I am using Waleed Abdulla’s Mask R-CNN for object detection and instance segmentation on Keras and TensorFlow. Also, I employ the technique described by Jason Brownlee in How to Train an Object Detection Model with Keras to detect kangaroos in images. Instead of kangaroos, I want to detect the type of construction used in building walls.
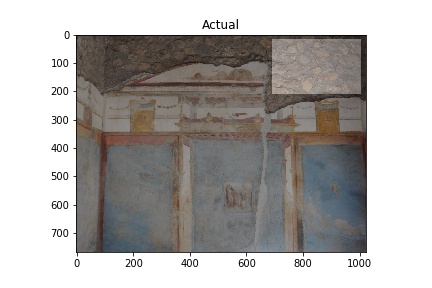
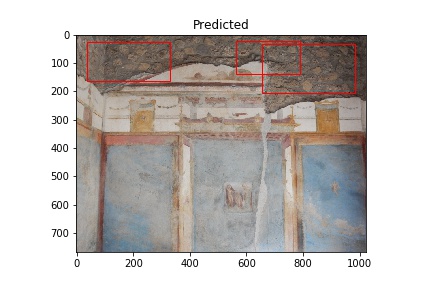
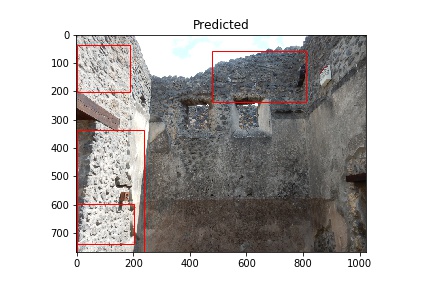
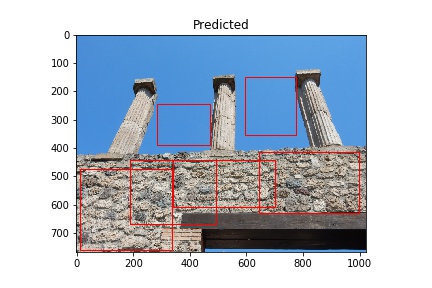
This is a brief post describing the preparation of images for training as well as the initial results. The images used are from the Pompeii Artistic Landscape Project and provided courtesy of Pompeii in Pictures. The original images were photographed by Buzz Ferebee and they have been altered by the program used for predictions. An example of an image showing the model’s detection of construction type opus incertum is below. Cinzia Presti created the data used to select the images for training.
The red rectangles note the model’s prediction of opus incertum as a wall construction type. Image courtesy of Pompeii in Pictures. Originally photographed by Buzz Ferebee.
To build this model, images were selected for training. Given the construction type is visible in only parts of each image, rectangles in each image show where the construction type is visible.
Image showing areas designated for training the model to detect opus incertum. File name: 00096.jpg. Image courtesy of Pompeii in Pictures. Originally photographed by Buzz Ferebee.
Each of the images has a corresponding xml file containing the coordinates of the rectangles that contain the objects used to train on. See file 00096.xml below:
The program to create the xml annotation files also saves images using a standard numeric file name (ex.: 00001.jpg) and width of 1024 pixels.
Initial Results
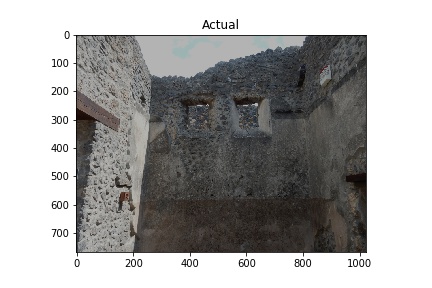
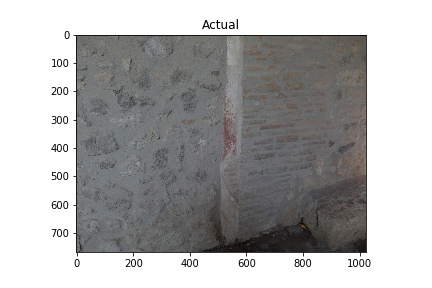
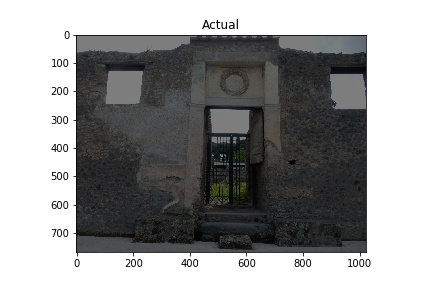
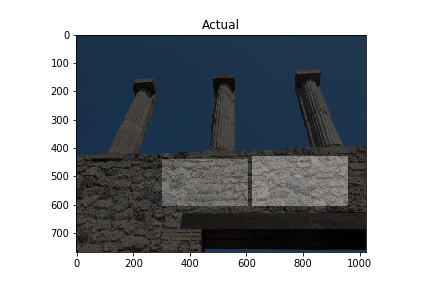
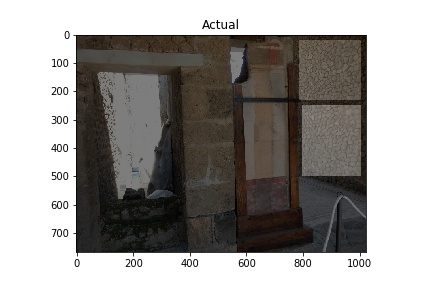
The “Actual” column of images below shows images used in training the model. The white rectangles show the boundary boxes contained in the corresponding xml file for the image. Some images don’t have a white rectangle. These images were deemed by me not to have a good enough sample for training so I didn’t make an xml file for them.
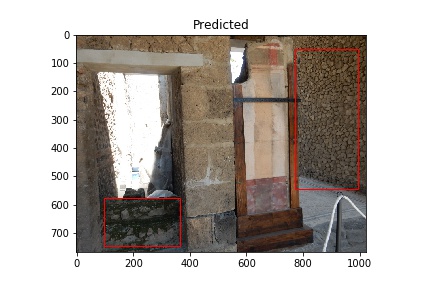
The “Predicted” column shows what the model considers to be opus incertum construction. Frequently it’s correct. It does make errors too, considering the blue sky in row 5 is recognized as stone work. I want to see if further training can correct this.
A couple things to note: It’s bad practice to run a model on images used to train it, but I am doing this here to verify it’s functioning. Later, I also need to see how the model performs on images with no opus incertum.
Training images (Actual) and Predicted images with red rectangles showing predicted matches from the model. Images courtesy of Pompeii in Pictures. Originally photographed by Buzz Ferebee.
References
Abdulla, Waleed. Mask R-CNN for object detection and instance segmentation on Keras and TensorFlow. GitHub repository. Github, 2017. https://github.com/matterport/Mask_RCNN.