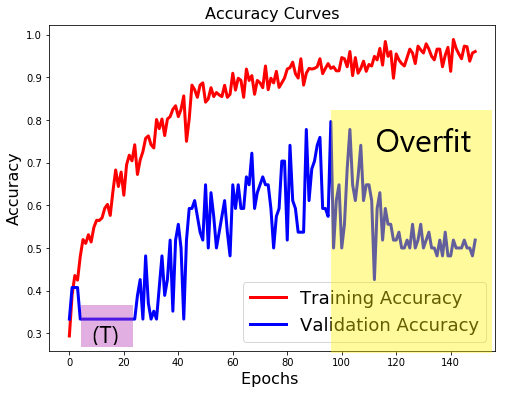
In Deep Learning for Python, François Chollet provides a “universal workflow of machine learning”. (Chapter 4, page 114.) I have been using his steps to seek the best performing image recognition model. I tried iterations of various models with different numbers of layers, filters and dropouts. An example of a model that did not provide a satisfactory level of accuracy is below.
def createModel5fail2():
#tried kernel_size=(5,5),
from keras import models
model = models.Sequential()
model.add(Conv2D(filters=32,
kernel_size=(5,5),
strides=(1,1),
padding='same',
input_shape=(image_width, image_height,NB_CHANNELS),
data_format='channels_last'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2),
strides=2))
model.add(Conv2D(filters=64,
kernel_size=(5,5),
strides=(1,1),
padding='valid'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2),
strides=2))
model.add(Flatten())
model.add(Dense(128))
model.add(Activation('relu'))
model.add(Dropout(0.25))
#number of classes
# 1,0,0 E-II
# 0,1,0 G-VI
# 0,0,1 G-VI
model.add(Dense(3, activation='softmax'))
return model In order to be more methodical and record my results I added a spreadsheet of model parameters (see models tab). These are the parameters:
- model_number – the identification number
- batch_size – the size of the batch. 8 or 16
- filters1 – the number of filters for layer 1.
model.add(Conv2D(filters=filters1, - dropout1 – Dropout (if greater than 0)
if(dropout1>0):
model.add(Dropout(dropout1))
- filters2 – the number of filters for layer 2.
- dropout2 – dropout for layer 2.
- filters3 – the number of filters for layer 3.
- dropout3 – dropout for layer 3.
- loss – the result of running the model.
- accuracy – (as above.)
The code to create the spreadsheet of parameters is here. (It’s just nested loops.) Below is the code to create a model from parameters fed from the spreadsheet. In the course of writing up this post, I found 2 bugs in the code below that are now corrected. Because of the bugs I need to re-run my results.
def createModelFromSpreadsheet():
from keras import models
model = models.Sequential()
model.add(Conv2D(filters=filters1,
kernel_size=(2,2),
strides=(1,1),
padding='same',
input_shape=(image_width, image_height,NB_CHANNELS),
data_format='channels_last'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2),
strides=2))
if(dropout1>0):
model.add(Dropout(dropout1))
model.add(Conv2D(filters=filters2,
kernel_size=(2,2),
strides=(1,1),
padding='valid'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2),
strides=2))
if(dropout2>0):
model.add(Dropout(dropout2))
if(filters3>0):
model.add(Conv2D(filters=filters3,
kernel_size=(2,2),
strides=(1,1),
padding='valid'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2),
strides=2))
if(dropout3>0):
model.add(Dropout(dropout3))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.25))
#number of classes
# 1,0,0 E-II
# 0,1,0 G-VI
# 0,0,1 G-VI
model.add(Dense(3, activation='softmax'))
return model
Below is the code to loop through each row of the model spreadsheet, create a model from the parameters, fit it and record the result.
number_of_models_to_run = 40
for number_of_models_to_run_count in range (0,number_of_models_to_run):
model_row = int(worksheet_config.cell(1, 2).value)
BATCH_SIZE = int(worksheet_models.cell(model_row, 2).value,0) #, 'batch_size')
filters1 = int(worksheet_models.cell(model_row, 3).value,0) #, 'filters1')
dropout1 = float(worksheet_models.cell(model_row, 4).value) #, 'dropout1')
filters2 = int(worksheet_models.cell(model_row, 5).value,0) #, 'filters2')
dropout2 = float(worksheet_models.cell(model_row, 6).value) #, 'dropout2')
filters3 = int(worksheet_models.cell(model_row, 7).value,0) #, 'filters3')
dropout3 = float(worksheet_models.cell(model_row, 8).value) #, 'dropout3')
print(str(model_row)+" "+str(BATCH_SIZE)+" "+str(filters1)+" "+str(dropout1)+" "+str(filters2)+" "+str(dropout2)+" "+str(filters3)+" "+str(dropout3))
# NB_CHANNELS = # 3 for RGB images or 1 for grayscale images
NB_CHANNELS = 1
NB_TRAIN_IMG = 111
# NB_VALID_IMG = # Replace with the total number validation images
NB_VALID_IMG = 54
#*************
#* Change model
#*************
model2 = createModelFromSpreadsheet()
model2.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
model2.summary()
epochs = 100
# Fit the model on the batches generated by datagen.flow().
history2 = model2.fit_generator(datagen.flow(tr_img_data , tr_lbl_data, batch_size=BATCH_SIZE),
#steps_per_epoch=int(np.ceil(tr_img_data .shape[0] / float(batch_size))),
steps_per_epoch=NB_TRAIN_IMG//BATCH_SIZE,
epochs=epochs,
validation_data=(val_img_data, val_lbl_data),
validation_steps=NB_VALID_IMG//BATCH_SIZE,
shuffle=True,
workers=4)
evaluation = model2.evaluate(tst_img_data, tst_lbl_data)
print(evaluation)
print(evaluation[0])
#record results
worksheet_models.update_cell(model_row, 10, evaluation[0])
worksheet_models.update_cell(model_row, 11, evaluation[1])
worksheet_config.update_cell(1, 2, str(model_row+1))
if(evaluation[1]>0.75):
number_of_models_to_run_count = number_of_models_to_run
print("Good Model - stopped")In the course of running these models, I had a model that provided 77% image recognition accuracy when tested and so I saved the weights. Due to the bugs I found I am re-running my results now to see if I can reproduce the model and find a better one.